打破人形机器人“数据慌”NVIDIA选择这样做
应用介绍
“通用”是机器人迭代演进的目标形态,这要求机器人具备高度泛化的感知、认知和决策能力,需要依托海量数据对具身模型进行训练。传统的人工数据采集方式难度大、要求高、效率低,成为制约机器人智能化水平提升的关键“卡点”,NVIDIA打造的数据合成解决方案成为破解“数据荒”的关键一招。
当前,具身智能无疑是风靡全球的流行热词,这项技术的发展,使机器人不再是只能执行预设程序的自动化装备,而是逐渐成为具有视觉感知、环境理解、自主决策和持续学习等综合能力的智能体,加快推动生产力重塑,赋能传统产业转型升级。
作为具身智能领域的“流量明星”,人形机器人的研发和应用被给予厚望。马拉松、拳击赛、足球赛等竞技活动引人瞩目,进工厂、进商店、进社区等实践案例不胜枚举,人形机器人商业化蓝海吸引无数创业者投身其中,然而由0到1的规模化应用突破仍然存在难以逾越的现实桎梏。近年来,国内人形机器人训练场在多地陆续设立,国外部分企业不惜斥重金雇佣人类员工训练机器人,诸如此类的消息频频引发行业关注,究其原因在于这背后蕴藏着共同的关切——数据——制约人形机器人智能化水平提升的“隐形门槛”。
如果说大模型是人形机器人的“大脑”,那么数据则是它“生长发育”所离不开的“养料”,这就不难理解数据为何会如此重要。举例而言,仅仅一个倒水的动作,就需要采集100条高质量数据供大模型训练,而在现实生活中,杯子的外形、位置千差万别,机器人想要灵活应对各种情况,就需要采用更大规模的数据集进行训练学习。因此,机器人领域存在一个普遍共识:海量数据训练是实现智能化的核心前提。

人形机器人的能力进化高度依赖数据“滋养”,而数据匮乏是行业面临的共性难题。现阶段,大语言模型已经得到成熟应用,融入社会生产生活的诸多方面,但人形机器人在行走、取物、交互等方面仍“蹑手蹑脚”,没有想象中灵巧聪慧,这就是数据量差异带来的直观表现。基于互联网数十年的发展积累,可用于训练大语言模型的数据量规模达PB级,但能用于训练人形机器人的有效数据却远不及此,尽管一部分整机企业开放了真机数据,但仍难填鸿沟。
一是行业发展起步晚,数据积累不足。人形机器人的高速发展集中在近5年,尽管此前工业机器人已经广泛应用于制造业,但由于其在物理结构、传感器配置、任务场景等方面均与前者存在显著差异,因此相关数据难以迁移至人形机器人。除此之外,由于各家厂商的机器人在本体设计、传感器配置等方面也存在区别,导致数据跨平台复用率低。
二是数据采集难度大、成本高。人形机器人的运行涉及视觉、力觉、触觉等多维感知信息,需要同步各传感器数据,时序对齐精度达毫秒级,现有技术误差容易导致动作失控;采集真实交互数据需部署高精度光学动捕系统,并依托专业操作员手把手示教,硬件采购和人员成本普遍较高,并且一旦涉及工业等真实作业场景,还可能占用产线资源,第三方配合意愿低。
三是“数据孤岛”现象突出。一方面,企业将数据视为核心竞争力,纷纷组建私有数据集,即便一些开源社区上线了共享数据集,但大多聚焦简单任务,复杂场景数据依然十分稀缺。另一方面,数据集缺乏统一的质量评估体系,难以规避错误标注带来的现实风险,例如错误的数据标注可能造成医疗机器人拿错药物,因而导致“数据信任”窘境。
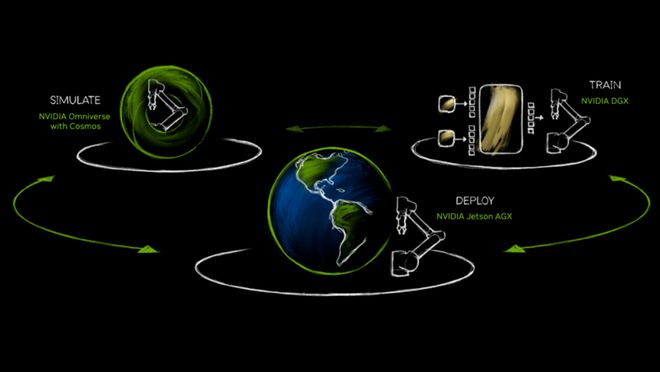
目前,行业普遍认同的数据破题路径主要分为两类,一是通过整合资源、规范标准、共建共享等手段多措并举,打造高质量真实数据集;二是借助物理仿真技术手段,降低真机数据采集成本,高效生成训练数据。针对前者,国家地方共建人形机器人创新中心、北京人形机器人创新中心等机构已经开展积极探索,收获显著成效。后者则涌现出了以NVIDIA为代表的科技企业先驱,基于深厚的行业积累,创新打造全栈机器人解决方案,帮助机器人开发者应对未来的技术挑战。
模仿学习是指人形机器人通过观察和效仿演示操作的方式获取新技能,这是机器人学习的一条重要途径。其中,“演示操作”可以是人类录制的真实视频,也可以是仿真数据。经过训练的人类演示员,平均每分钟可以录制一段高质量示范动作,但由于这种传统的数据采集方式需要大量人力支持,且存在出错的可能,因此难以大规模推广。相比之下,NVIDIA推出的NVIDIA Isaac GR00T Blueprint,能够基于少量的人类演示数据创建大量合成运动轨迹,并用于训练机器人。测试结果表明,GR00T Blueprint可以在11小时内生成780,000个合成轨迹,相当于人类演示员连续9个月采集的数据总量。此外,GR00T Blueprint生成的数据还能与真实世界数据相结合,进一步提升数据的质量和规模,从而达到与人类演示数据相似的训练成功率。
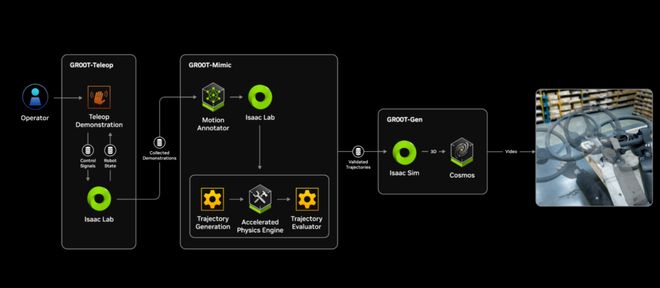
从运行逻辑上看,GR00T Blueprint的工作流程可分为数据采集和生成合成轨迹两部分。在数据采集阶段,NVIDIA Isaac Lab平台会生成机器人环境仿真,操作者通过佩戴Apple Vision Pro等高保真显示设备沉浸式观察作业环境,其手部动作被Apple Vision Pro实时采集并传输回Isaac Lab平台,以此让操作者直观地控制仿真世界中的机器人执行任务,完成示教操作。在生成合成轨迹阶段,Isaac GR00T-Mimic会从少量的人类示范中推算出大量合成运动轨迹,这个过程包括在示范中标记关键点,使用插值法合成平滑且符合情境的运动轨迹,以及对生成的数据进行评估和优化等,确保仿真数据满足训练标准。
仿真数据的生成过程看似简单,但要想缩小仿真和现实之间的训练差距,就需要使合成的机器人和场景具有足够逼线D效果,并通过随机设定照明、颜色和背景等各种参数来增加多样性。通常,仿真的过程需要由专业的建模人员耗费大量时间完成。如今,借助NVIDIA推出的Cosmos Transfer(WFMs),只需简单的文本提示,就能生成高质量仿真场景,将耗时从数小时缩短至几分钟,大幅提升了建模效率。
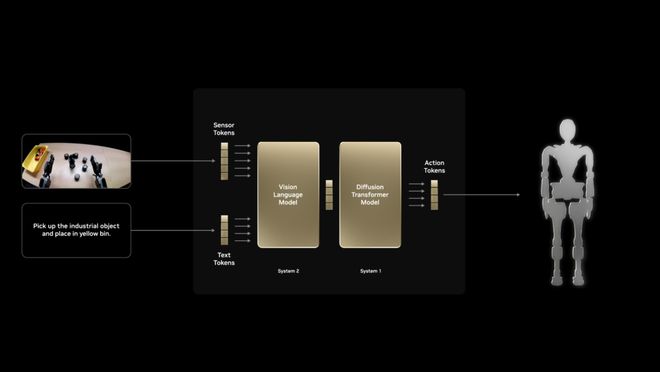
通过利用合成数据集进行真实训练,NVIDIA验证了这项解决方案的实用价值。Isaac GR00T N系列模型是NVIDIA打造的用于通用人形机器人推理和技能的开源基础模型,能够流畅处理文本指令与图像等多模态输入,输出机器人动作指令,具备出色的跨实体、跨任务泛化能力。该模型基于来自互联网的大规模数据和人类视频进行训练,此外还补充了通过GR00T Blueprint生成的合成数据,将这些合成数据与真实数据相结合后,与仅使用真实数据进行训练的情况相比,GR00T N的性能能够提升40%。2025年5月,NVIDIA发布了Isaac GR00T N1.5,借助GR00T-Dreams Blueprint生成合成训练数据,研究人员仅用36小时就完成了GR00T N1的迭代升级。如果采用人工数据收集的方式进行训练,该过程则需耗时近3个月。
近年来,越来越多的科技企业选择运用NVIDIA Isaac平台技术,加快推进人形机器人的开发与部署。
作为生成式AI与仿真技术合成数据提供商,光轮智能成功将GR00T N1人形机器人基础模型部署至汽车制造生产线模型在行业场景的首次实战应用。通过构建物理交互真实、场景多样化的仿真环境,光轮智能模拟了汽车工厂中的复杂任务场景,并基于“人在环”的仿真遥操作,生成了覆盖各类任务的大规模遥操作合成数据。这些高质量合成数据不仅加速了GR00T N1模型的训练过程,还通过“Real2Sim2Real+Realism Validation”技术架构,有效缩小了仿真环境与物理现实世界的差距,确保训练成果能够顺利迁移至真实应用场景,从而大幅提升模型在实际环境中的表现水平。在汽车工厂中,搭载GR00T N1模型的人形机器人装载通过质检的零部件并批量搬运放置到精确位置的动作,展现了其在工业场景中的应用潜力。两者合作为具身智能进入智能制造树立了新范式。

通用具身机器人领域的“明星企业”智元机器人,推出了基于Isaac GR00T-Teleop和GR00T-Mimic技术的仿真大规模数据采集方案和海量开源仿真数据集AgiBot Digital World,高效解决机器人数据稀缺的问题。智元机器人的仿真数据生成方案,借助Isaac Sim高度逼真的视觉渲染和精确的物理引擎,精准还原机器人的训练环境,并结合GR00T-Teleop远程操作和GR00T-Mimic的数据增广技术,快速生成高质量且多样化的专家轨迹数据,不仅大幅降低了数据采集的成本和时间,还为机器人模型训练提供了丰富的仿真数据资源,帮助机器人更高效地融入人类社会,推动各行各业的智能化转型。
专注于具身多模态大模型通用机器人研发的创新企业银河通用,借助Isaac Lab和Isaac Sim搭建了灵巧手抓取模型的仿真测试环境,显著加速了对于灵巧手抓取模型Scaling Law的探索进程,以及灵巧手泛化抓取技能在真实应用场景中的落地进程。
随着生成式AI与物理仿真的深度融合,机器人加速由“专用工具”向“通用数字劳动力”转型。正如黄仁勋所言:“通用机器人时代已经到来。”NVIDIA正依托全栈机器人解决方案,与全球开发者共同开启人机协同新纪元。