如何将研报PDF转化为结构化数据?
应用介绍
随着数字经济加速渗透,数据要素市场化配置成为政策聚焦重点,《数据要素市场化配置综合改革试点总体方案》等政策明确提出 “推动非结构化数据价值挖掘”。在金融领域,研报作为承载行业分析、投资决策的核心载体,多以 PDF 格式的非结构化文档存在,包含大量文本、表格、图表等异构信息。当前,金融机构面临 “数据孤岛”“非结构化数据利用率低” 等痛点 —— 据行业调研,超过 70% 的金融研报数据因格式限制无法直接用于业务分析或智能决策,亟需高效工具实现从非结构化文档到结构化数据的转化,以适配企业数据库建设、RAG 应用、智能问答等数字化需求。
是金融领域典型的非结构化文档,通常以PDF文件格式存在,内含文本描述、复杂表格(如财务报表)、多维图表(如趋势分析图)等元素,版式灵活但缺乏统一数据结构,难以被计算机直接识别和处理。
:指具有固定格式、逻辑清晰的数据形式(如数据库表、JSON、Excel 等),可被快速搜索、统计分析、集成到业务系统,并支持自动化处理(如批量计算、智能建模)。
:将研报 PDF 转化为结构化数据,本质是打破 “文档壁垒”,让分散在 PDF 中的信息成为可复用、可挖掘的数据资产,为金融机构的业务分析、决策支持提供底层数据支撑。
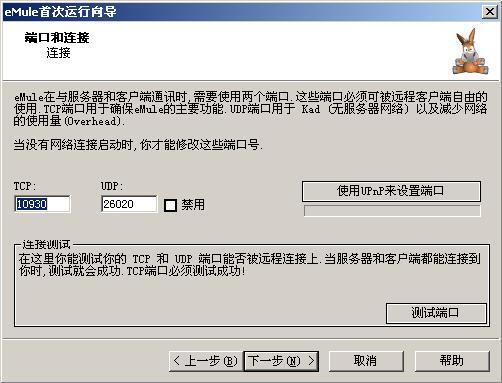
Textln文档解析可将版式复杂、内含大量表格或者图表元素的研报转化为结构化数据,使其变得可搜索、可分析、可集成和可自动化,在研报解析领域具备成熟技术积累:
Textln文档解析提供全链路的文档结构化工具,可将研报转化为可操作的数据资产,最大化挖掘数据资产价值,最终应用于企业数据库、业务分析、RAG应用、智能问答等。
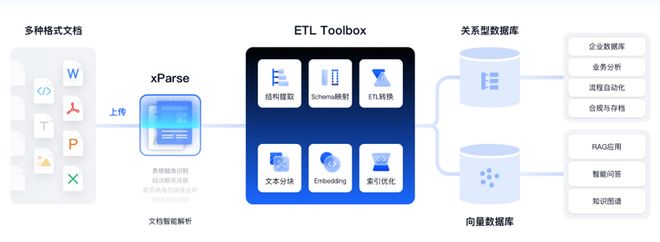
Textin文档解析拥有出色的表格解析能力,不仅支持有线表,还能精准识别无线表、跨页表格、合并单元格、密集表格、行列数不同的不规则表等难点,保障表格信息无损转换,防止转换过程中出现数据丢失或变形的问题。
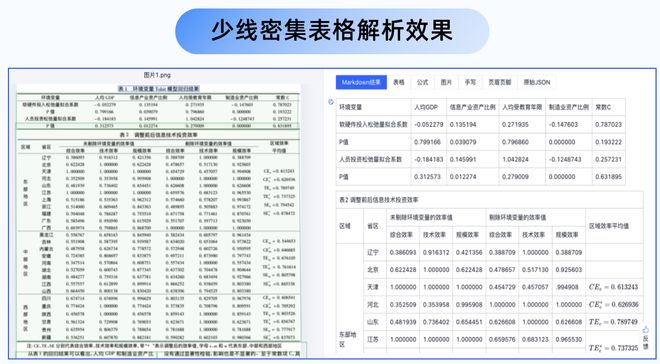
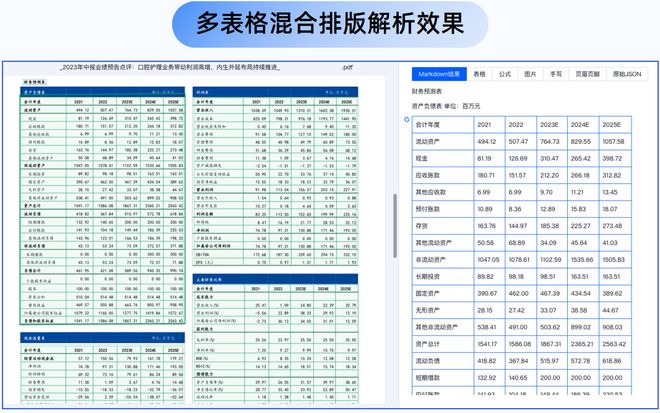
研报中,图表经常被运用于记录和直观表现数据。但想要逆向将这些PDF或图片格式的图表转化为结构化数据,却非常困难。
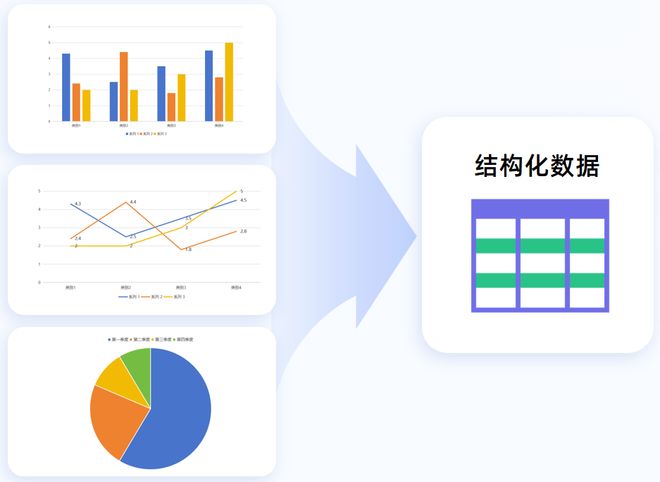
Textln文档解析拥有图表解析能力,可以将非矢量格式的图表解析为结构化数据,帮助大模型深度理解图表的结构趋势和数据逻辑。当前功能已支持柱状图、折线图、饼图:雷达图、散点图等多种图表类型.
与传统 OCR 工具仅实现格式转换不同,TextIn 文档解析的核心价值在于保留数据语义与业务逻辑:
不仅能提取研报中的文本、表格、图表信息,更能识别数据间的关联(如某公司营收数据与行业对标分析 的逻辑关系),让结构化数据具备业务可读性;
通过将研报转化为标准化数据资产,帮助金融机构缩短“信息获取 - 决策输出”的链路 —— 例如,分析师可直接调用结构化后的研报数据进行批量对比分析,智能问答系统可快速定位研报中的关键结论,大幅提升工作效率;
目前已服务超 500 家金融机构,包括券商、基金公司等,助力其将历史研报库转化为动态更新的数据中台,最大化挖掘沉淀数据的资产价值。