百度网址安全中心这个神秘的组织如何为世上所有的网址“验明正身”? 深度
应用介绍
当你推开一扇门的时候,很可能并不知道自己将会身处险境。这时,你可能需要一只“上帝之手”,在你误入歧途的一瞬间,把你拉回人间。
百度,注定不能做一个安静的推荐者。因为人们期待并且要求它为推荐的结果负责。所以,在把网址链接呈现给用户之前,即使是刀山油锅,网址安全中心的童鞋们也要为用户“尝试”一下。
那么,这个安全中心究竟如何运作,其中又有什么有趣的技术呢?雷锋网宅客频道采访到了百度商业安全研发部技术总监冯景辉,他负责百度安全旗下企业安全产品的研发工作。
这类网页会隐藏恶意脚本,利用你的系统漏洞安装木马病毒。如果你的系统没有升级到最新版本,有可能被木马“钻”进来。木马一旦“进驻”就会进而获取你的隐私信息,或者远端控制你的电脑。
这三类网址可以统一归为违法网址。它们所宣扬的内容本身并不合法,严重影响社会安定,所以显然属于恶意网址范畴。
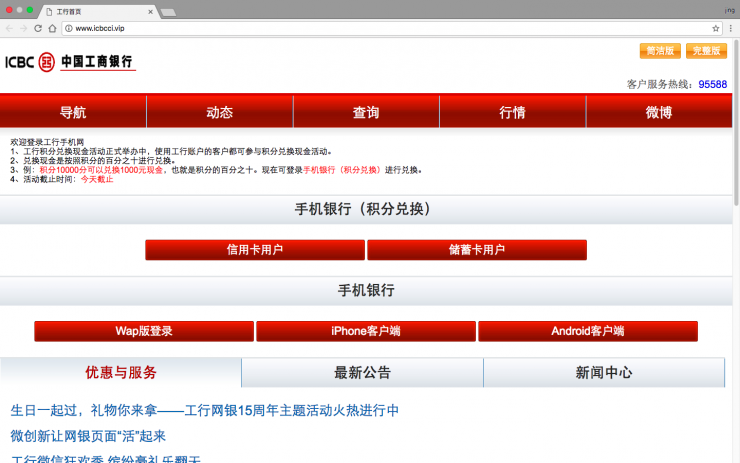
严格地说,这类网址本身的存在并不违法,但它们是诈骗环节的一部分。例如:仿冒的银行网页,虚假的中奖信息网页。骗子会通过各种渠道把这些网址发送给受害人,诱骗他们填入密码等信息,进而盗取银行欠款,或者进一步诈骗。
这些恶意网站,背后被不同的经济模式所驱动。在金钱的诱惑面前,总会有人铤而走险。中国境内恶意网址的数量,甚至超过了我们的人口。
1、所有恶意网址中,数量更大的是钓鱼网址。这些页面中,有70%是“虚假中奖”“虚假购物”这类诈骗网页,而其余30%则是针对银行或电商的“仿冒网站”。
和所有诈骗一样,这类网址一般是“打一枪换一个地方”。网址链接(URL)的平均存活时间,国际上是29小时,而在中国是33小时。
2、黄赌毒网页的绝对数量不多,但是访问量在所有恶意网址中所占的比例更高。和钓鱼网站不同,这类网站需要“长期运营”。(看来,和人性的斗争确实艰苦卓绝。)
看上去,恶意网址都是那么地“个性鲜明”,判断一个网址是不是属于恶意网址似乎很简单。但是仔细分析,你会发现至少面临两个巨大的技术困难。
回到最初的比喻,如果用街道上的门来比喻一个个网址,搜索引擎爬虫的主要任务是把那些“门”里的大致情景记下来,然后在需要的时候呈现给用户。为了精确,有事还会推开门拍一张厅堂的“快照”(网页快照)。
但是,这样的爬虫并不能“感受”到在房间内部究竟有怎样的“机关暗道”。这时,你需要“战斗爬虫”。
“战斗爬虫”不仅仅是“看一眼”或“拍张照”这么简单,而是把所有的门都探索一遍。一些网页会存在跳转、加密。“战斗爬虫”要做的,就是利用种种技术手段,把房间中的暗门和夹层全部记录下来。
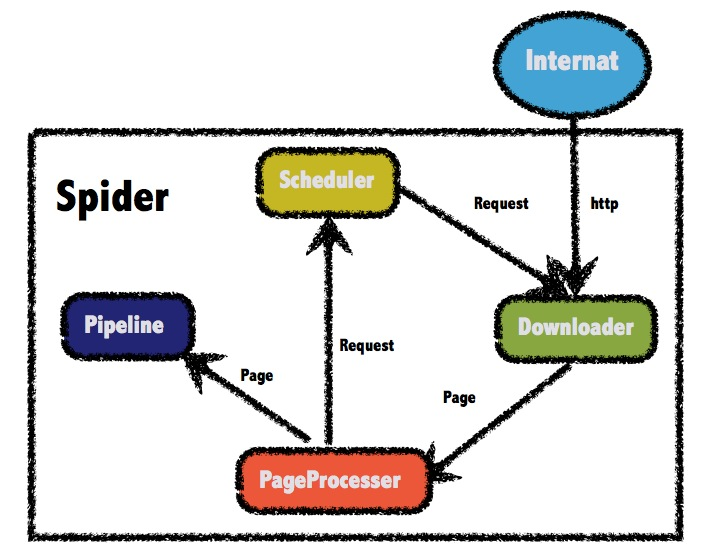
爬虫系统的输入源,包括百度搜索的结果内容,还包括百度内部的贴吧等内容,也有手机卫士安全客户端报告的高危网址,还包括合作方提供的URL。
当然,检测恶意网址最可靠的 *** 就是交给人工。但是,面对如此庞大的网址数量,全国人民一起上阵都未必忙得过来。
所以,这些资料会统统交给一位经验丰富的“老刑警”来搞定,这个老刑警就是“网址安全检测引擎”。
木马传播到电脑上,一般都会利用漏洞,而这些漏洞都有“特征内容”。利用对这些特征的识别,就可以判断出网页是否有挂马行为。但是,很多黑产也会采用加密、变形等手段增加我们的检测难度。我们主要在对抗这些手段。
有些网页在脚本中隐藏了恶意木马,但是这种隐蔽 *** 和一些病毒类似,需要在真实的网页环境中才会被触发。对于这类“嫌疑网页”,百度网址安全中心的童鞋们会利用类似“沙箱”的系统,让网页脚本跑在虚拟机中,让它露出“真面目”。
对于“黄赌毒”内容的检测,和传统反病毒所需的技术差别很大。实际上,引擎所要做的基本任务,就是根据网页内容把它进行分类。
所谓 TF-IDF 算法,简单说来就是提取网页内能够表述网页内容的关键词,找到在这个网页中出现频繁,但是其他网页中并不普遍的词汇。
既然黑产的目的是“像”,那么对抗的技术就是“对比相似性”。这其中又主要用到一种数学算法:SIMHASH 算法。
简单说来,SIMHASH 算法就是把一个网页内容转换成一个64位的“特征字”,如果两个内容的特征字距离小于规定值,那么就判定二者相似度极高。这种算法最早由谷歌研发,用于网页搜索去重。
写过毕业论文的童鞋都知道,从网上 Down 哪怕一段内容,都会被论文查重系统的火眼金睛发现。没错,老师们正是用 SIMHASH 这种“人类智慧的结晶”在和“不法学生”对抗。
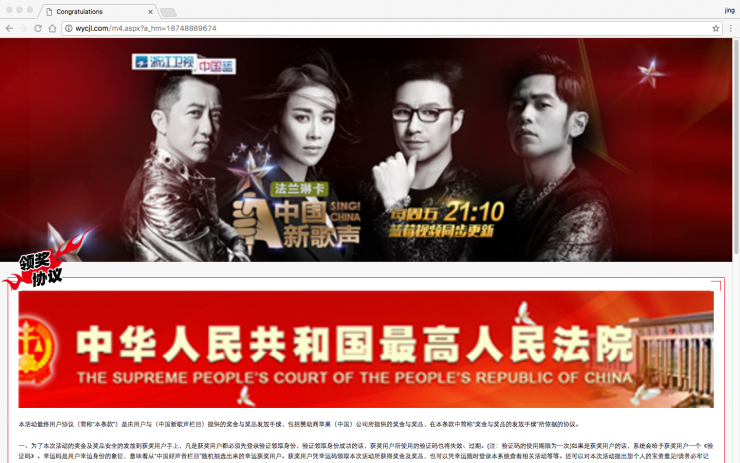
然而,在钓鱼网页中,还有70%的“虚假中奖”类页面,它们并没有仿冒其他网页,这对于冯景辉和团队来说,是一个不大不小的难题。
判断一个网页是不是“虚假中奖”页面,对于一个人来说,可能是小菜一碟。如果可以训练机器来模拟人的判断,问题就会迎刃而解。
类似的特征还有很多,把这些特征参数放到深度学习引擎中,机器就可以自己总结出一套判定“虚假中奖”页面的标准,实现自动的智能识别。
例如一些小说站和图片站。对于描写的尺度、内衣的高度(为了防止本文被判定为黄赌毒网页,就不多说了)这些擦边程度的判断,只能人为地划定标准(参考车展和 ChinaJoy 为美女“量身定做”的“两厘米”规则。。。),然后把这些标准输入深度学习系统,把这种让人“心力交瘁”的工作甩给机器。
以上这种深度学习的 *** , 被称为“有监督学习”,简单来说,就是需要人类不断提供一些特征标准,机器根据这些特征进行下一步总结。但是冯景辉说,他们下一步想要搞的,是“无监督学习”。
无监督学习,就是根本不告诉人工智能系统任何“人类总结出的特征”,仅仅是给它大量的黑白样本,让系统自动抽象出一些特征。人类只负责告诉机器它的判断是对还是错,机器根据这个结果来改进它总结的特征。
这些特征往往非常奇葩,有些以人类大脑的逻辑并不容易总结和表述。但是,这类“无法描述”的特征往往一针见血,精准异常。
充斥着黑产的赛博世界从来都是“Hard”模式。要知道,冯景辉和团队面对的是无数“老司机”,“束手就擒”这四个字从来就不在他们的字典里。
很多黑产为了躲避对违法文本内容的打击,会把这些文本做成图片的形式。当然,图片上的 OCR 文字识别技术已经很成熟了。我们需要做的,就是把这种技术重新部署进我们的系统,不断升级对抗的手段。

在“林丹”事件被爆出的那一刻,反应最快的不是林丹,不是谢杏芳,而是黑产。他们手中控制了一个僵尸网站群,在之一时间把这一站群的集中引用页面的关键词都改为“林丹”,这样,这一站群的关键词都会成为林丹,被搜索引擎自动匹配关联。
由于平时这些黄色网站群处于“蛰伏”状态,不一定被“战斗爬虫”和“检测引擎”发现。此时它们突然大规模跳出,借助人们对于林丹的“如火热情”,可以大赚一票。
另外,百度搜索引擎有联想功能,可以关联两个相关的词汇。例如:人们会搜索某个明星的名字,但是名字比较复杂,很多人之一次输入错误,搜索之后又更正为正确的重新搜索。这时,搜索引擎就会自动关联这两个词汇。
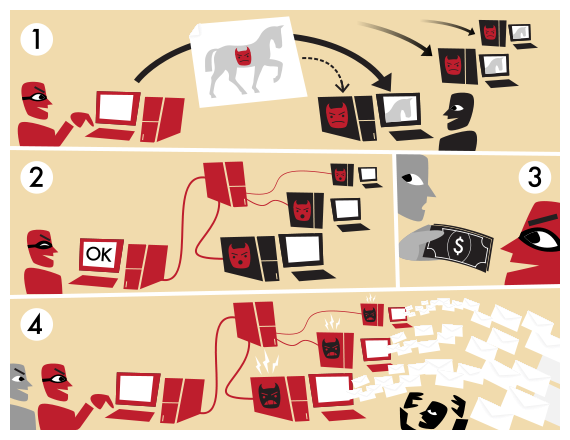
黑产会利用机器学习的这一特性,发动手上的肉鸡不断同时搜索两个关键词,这两个关键词,一个是正常的热点词,另一个就是黑产页面的关键词。这样的话,每当用户搜索热门关键词的时候,就有可能搜索到黑产相关的页面。
在搜索引擎改进对抗机制的同时,网址安全中心的技术团队也会优先排查和热点词相关联的页面是否安全。
有一些开放的平台,允许用户上传信息。这时,如果黑产在上面发表了带有有害链接的帖子评论,就会引发大量的点击。这种链接传播更广,危害也会更大,需要在之一时间筛查,我们必须优先保证可能被访问最多的网页是最安全的。
这样的玩法,正是为了躲避检测引擎中“沙盒”的虚拟执行。而在得知黑产采用这种对抗策略后,冯景辉和童鞋们就在检测 *** 中增加了针对性的策略。
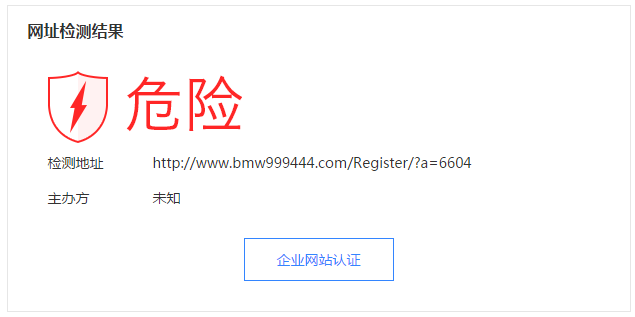
某些恶意网页会把百度和其他安全公司的 IP 列为“黑名单”,一旦发现被这些 IP 访问,就装作“乖宝宝”,自始至终不展开恶意行为。
在对抗中,黑产发现安全人员总能找到新的 *** 来对抗,于是干脆采用了“断臂求生”的 *** ,网页在白天关闭,只在夜间开放。
目前,百度网址安全中心的检测结果会提供给微软、百度、爱奇艺、小米路由器、火狐浏览器、新浪微博等合作伙伴。由这些终端来执行弹窗提示、网页屏蔽或者实时阻断。
互联网的自由在于,你可以不受限制地推开每一扇门。但一扇扇形形的门背后,可能是温馨浪漫的花园,也可能是蛇蝎暗藏的幻境。
存在着欺骗和攫取的互联网,并不是天堂,它只是我们的现实在赛博世界的翻版。我们在大多数时候对自己的判断力自信无比,但我们的父母,我们的孩子却可能坠落陷阱。
百度网址安全中心,也许还没办法做到对恶意网址 100% 的判定。但所有的人的努力,都是为了逼迫恶意网址的领地不断减少。